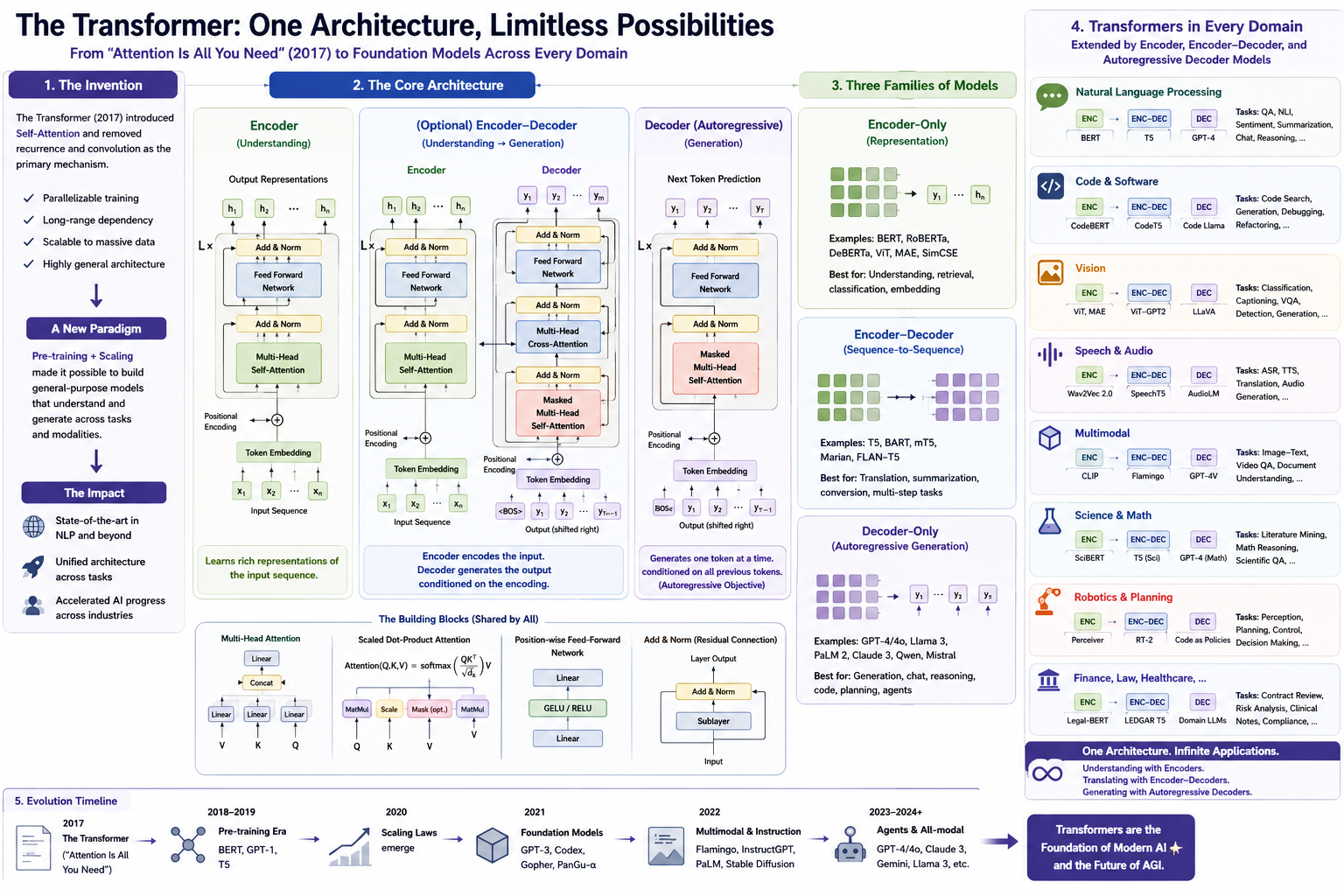
為什麼要從 Transformer 看起
為什麼 LLM 可以突然變得這麼強?為什麼過去幾年許多不是 LLM 的 AI 技術,也一起快速進化?這張圖剛好把一個可能的共同答案整理出來:很多突破背後,都和 Transformer 這套架構有關。
這張圖在說什麼
這張資訊圖的主題是「一個架構,無限可能」。它從 2017 年論文 Attention Is All You Need 出發,說明 Transformer 如何用 self-attention 取代 RNN 與 CNN 作為主要機制,進而成為今天大型語言模型、圖像模型、多模態模型與 AI agent 的共同底層語言。
Attention 改變了 AI 理解資訊的方式
Transformer 最重要的核心是 attention。它讓模型可以理解一段內容裡,每個 token 彼此之間的關係。以前很多模型比較像照順序讀,但 Transformer 可以同時看整段內容,判斷哪些資訊有關、哪些資訊更重要、哪些資訊需要被保留。當資料被 token 化、向量化之後,模型就能透過大量參數學習這些關係。
為什麼它不只適用文字
這個架構厲害的地方,是它不只限於文字。文字、圖片、聲音、影片、蛋白質序列、機器人動作,只要能被切成 token 或類似 token 的表示,就可以被放進 Transformer 類型的模型裡學習。這也是為什麼近幾年不只 LLM 變強,視覺、語音、多模態、科學計算與機器人領域也一起加速。
LLM 只是預測下一個 token,為什麼會有理解能力
LLM 表面上的訓練目標很簡單:根據前面的內容,預測下一個 token。但當資料夠多、模型夠大、訓練夠久後,模型會開始展現一些原本沒有人明確寫死的能力,例如抽象理解、歸納、語意轉換、推理與多步思考。它本質上仍然是在算機率,但要能長期正確預測下一句話,模型必須在內部建立語言結構、世界知識、邏輯關係與概念映射。
中間:核心架構如何運作
中間是整張圖最重要的技術核心。Encoder 負責把輸入序列轉成高品質表示,Decoder 負責根據已生成的 token 一步步預測下一個 token,而 Encoder-Decoder 則把「理解輸入」與「生成輸出」接在一起,適合翻譯、摘要與 sequence-to-sequence 任務。底部補上共同積木:multi-head attention、scaled dot-product attention、position-wise feed-forward network,以及 residual connection 加 layer normalization。
右中:三大模型家族
圖的第三部分把現代 Transformer 模型整理成三個家族。Encoder-only 偏向表徵與理解,例如 BERT、RoBERTa、DeBERTa,常用於搜尋、分類、檢索與 embedding。Encoder-Decoder 偏向輸入到輸出的轉換,例如 T5、BART、mT5、FLAN-T5,常見於翻譯、摘要與多步轉換任務。Decoder-only 則是自回歸生成,例如 GPT-4/4o、Llama 3、Claude 3、Qwen、Mistral,適合聊天、推理、寫程式、規劃與 agent。
右側:同一架構跨到每個領域
最右側展示 Transformer 的可遷移性:自然語言處理、程式碼、視覺、語音與音訊、多模態、科學與數學、機器人與規劃,以及金融、法律、醫療等專業場景。每個領域都可以找到 Encoder、Encoder-Decoder 或 Decoder 的變體,差異在於資料形式、任務目標與訓練方式,而不是完全重造一套架構。
一個有趣的直覺:預測也許是智慧的一部分
想到 next token prediction 時,最有趣的地方是:人腦某種程度上也一直在根據過去資訊,預測下一步世界會怎麼變化。當然,人腦和 LLM 的運作方式完全不同,不能直接畫上等號;但「透過預測來建立對世界的壓縮表示」這個直覺,確實能幫助理解為什麼單純的預測任務,最後可能長出看似理解與推理的能力。
底部時間線:從論文到 Foundation Models
底部時間線把演進壓縮成幾個節點:2017 年 Transformer 出現;2018 到 2019 年進入預訓練時代,BERT、GPT-1、T5 等模型奠定基礎;2020 年 scaling laws 開始成為共識;2021 年 foundation models 興起;2022 年多模態與 instruction tuning 普及;2023 到 2024 年則進入 agents 與 all-modal 模型階段。這條線說明 Transformer 不只是單一模型,而是一個持續擴張的平台。
如何讀這張圖
如果你是第一次看 Transformer,可以先從中間三個架構開始,理解 Encoder 是「讀懂」、Decoder 是「生成」、Encoder-Decoder 是「讀懂後再生成」。接著看右中的三大模型家族,把熟悉的模型名稱放回對應位置。最後再看右側應用與底部時間線,就能理解為什麼同一個 Transformer 架構能同時出現在 ChatGPT、程式碼助手、圖像理解、語音模型、機器人控制與專業文件分析裡。